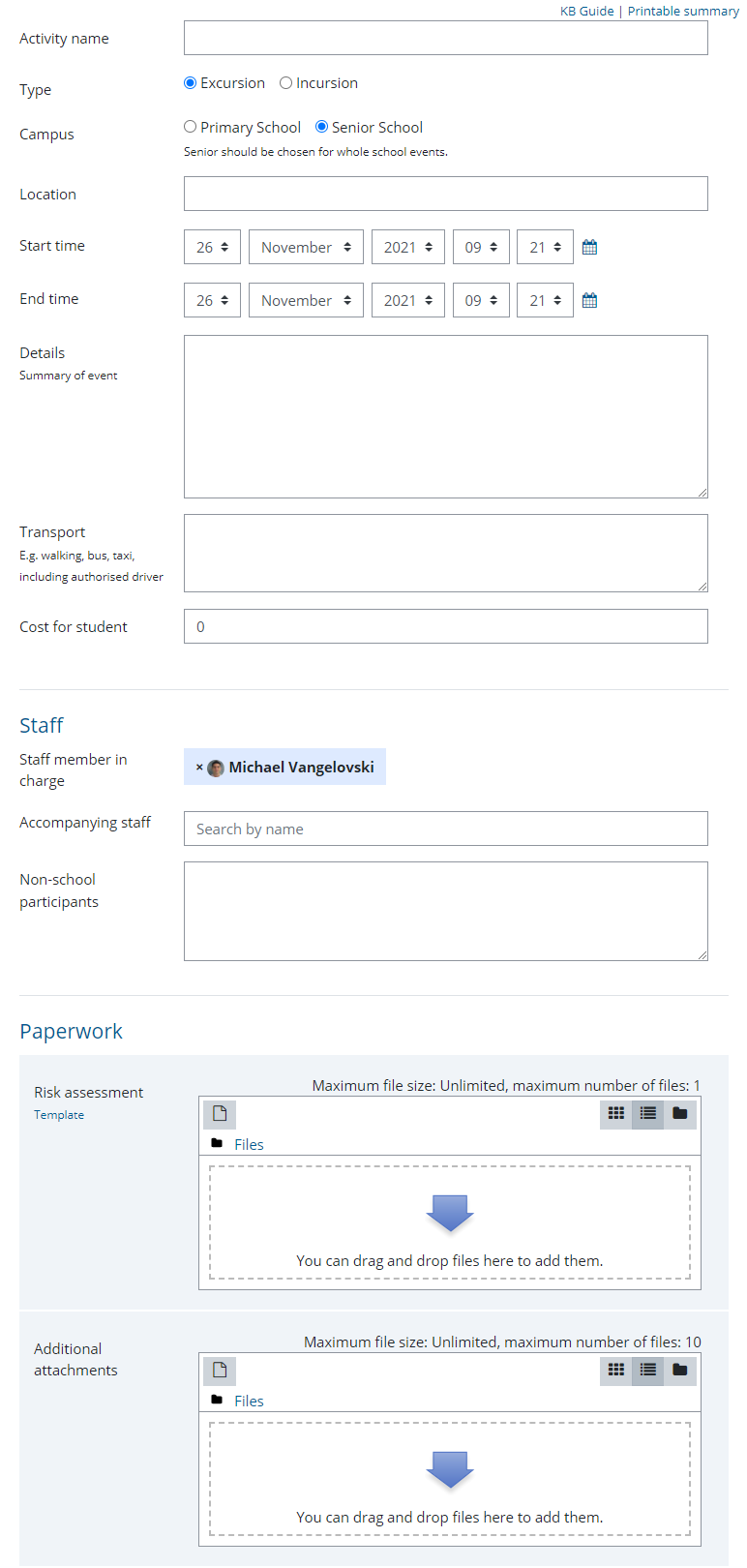
Check out the finished product here: tradesact.com.au
What is Serverless?
Web applications typically have a backend (application logic and database) and frontend (user interface). In past times, the backend and frontend were both part of the one application. The backend would execute application logic (C#, PHP, Java), access the database (SQL), and then generate and serve the frontend (HTML/CSS/JS) to the browser. In recent years there has been a shift away from this towards a decoupling of frontend and backend logic. This allows independent technologies and infrastructure to be used for each. Modern frontends are typically built using a JS framework, such as Vue or React, and backends have become API endpoints, controllers and data stores, built using a framework like .NET, Laravel or Django. These applications are hosted on traditional server stacks such as Linux, Apache, MySQL & PHP.
Even more recently, there is the notion of “Serverless” web apps. Serverless does away with traditional hosting and traditional backend frameworks (Laravel, Express, etc), replacing both of these with managed services by cloud providers such as AWS, Azure, Google, Heroku, Netlify, Cloudflare and Supabase. Using a cloud provider, you can stitch together a set of services that essentially mimic a backend. These cloud services allow you to run application logic via HTTP endpoints (Functions as a Service) and access data stores. The functions spawn, execute and scale on demand. You don’t have to worry about the framework or servers on which they run. Databases and stores are also managed by the provider. You can use a single provider like AWS which has 100’s of services covering every facet of cloud computing, or stitch together services from multiple providers that do certain things well or cheaply. For example, Wasabi for object storage and Auth0 for user management. Many traditional hosting providers like Dreamhost, Linode, and DigitalOcean are now releasing services like object storage, FaaS, and managed databases. You are free to pick and choose providers and services to form your architecture. I went with a mostly AWS architecture for simplicity. It has the most mature offering with plenty of official and community docs.
My Serverless project
I built tradesact.com.au as a Serverless learning exercise. I started with Azure and moved to AWS using the SST framework for reasons mentioned above. The SST framework provides higher level constructs for the AWS CDK, which makes it really easy to develop and test your application. At deploy time, I used Seed, the CI platform built by the people behind SST. I discovered that AWS’s relational database offerings are quite expensive, so I switched to DigitalOcean’s managed Postgres service for the production database. I am using Heroku’s free tier for development and staging databases.
One of the caveats of the Serverless model is that you pay for what you use, and there is seemingly no limit as to how much your services can scale. Theoretically, you could be hit with a DDoS attempt resulting in your services to spike at a huge expense to you. Therefore, I’ve proxied access to the services through Cloudflare to provide some mitigation against these types of attacks.
The architecture
I use the following set of services to run tradesact.com.au.
Setting up the stacks
The infrastructure above is provisioned almost completely from code containing SST and AWS CDK constructs. The code is converted to CloudFormation templates internally which are used to provision all of the AWS services and resources. Some initial setup is needed, including creating an AWS account, IAM user, and installing the AWS CLI.
Buckets
I created an “Uploads” bucket in S3 to store file uploads such as logos. Within this there are public and private folders.
this.bucket = new sst.Bucket(this, "Uploads", {
s3Bucket: {
cors: [{
allowedMethods: ["GET", "PUT", "POST", "DELETE", "HEAD"],
allowedOrigins: ["*"],
allowedHeaders: ["*"],
maxAge: 3000,
}],
},
});
const s3BucketPolicy = new BucketPolicy(this, 'S3BucketPolicy', {
bucket: this.bucket
})
s3BucketPolicy.document.addStatements(
new iam.PolicyStatement({
actions: ["s3:GetObject"],
effect: iam.Effect.ALLOW,
resources: [
this.bucket.bucketArn + "/public/*",
],
principals: [new iam.AnyPrincipal()],
}),
)The CORS configuration allows client access to the uploads bucket from the dev domains. A policy is added to the S3 bucket to allow public read access to the “public” folder. This allows direct access to objects like logos via their S3 URL, otherwise the app has to use a Signed URL which can be obtained from the Amplify Storage API. The staging and public sites will only be accessible via Cloudfront, so this policy is overwritten for those.
Authentication
To manage sign up and login functionality for users, I used an Amazon Cognito User Pool. It stores the user’s login info. It also manages user sessions in the Vue app.
const userPool = new cognito.UserPool(this, "UserPool", {
selfSignUpEnabled: true,
signInAliases: { email: true },
signInCaseSensitive: false,
lambdaTriggers: {
postConfirmation: postConfirmationFunction,
preSignUp: preSignUpFunction,
},
standardAttributes: {
email: {
required: true,
mutable: true
},
givenName: {
required: true,
mutable: true,
},
familyName: {
required: true,
mutable: true,
},
}
});The code above creates the user pool. It allows users to sign up, with email, first and last name. It allows for login using email (as opposed to username which is only used internally). I’ve added two triggers to the signup process. preSignUp automatically confirms the user and verifies the email. This simplifies the signup flow by putting the user into an active state without requiring email address verification. postConfirmation makes a copy of the pertinent user information in the database so that we do not need to interact with Cognito in the application beyond the user management services it offers us. Finally, a user pool client is created with SRP enabled to allow the web app to authenticate users via Amplify. The auth stack is complete with a user pool, client, and an identity pool.
Policies were then added to specify the resources authenticated users have access to. In this case, authenticated users need access to the API and S3 bucket.
this.auth.attachPermissionsForAuthUsers([
this.api,
new iam.PolicyStatement({
actions: ["s3:*"],
effect: iam.Effect.ALLOW,
resources: [
this.bucket.bucketArn + "/public/*",
this.bucket.bucketArn + "/protected/${cognito-identity.amazonaws.com:sub}/*",
this.bucket.bucketArn + "/private/${cognito-identity.amazonaws.com:sub}/*",
],
}),
new iam.PolicyStatement({
actions: ["s3:GetObject"],
effect: iam.Effect.ALLOW,
resources: [
this.bucket.bucketArn + "/protected/*",
],
}),
]);I created an IAM policy to secure the files users will upload to the S3 bucket. We add the user’s federated identity id to the path so a user has access to only their folder within the bucket. This allows us to separate access to the user’s file uploads within the same S3 bucket.
API
The API, via API Gateway, is what joins the front end to the backend logic. It exposes HTTP endpoints for use by the Vue.js client.
const authorizer = new HttpUserPoolAuthorizer('APIAuthorizer', this.auth.cognitoUserPool, { userPoolClients: [this.auth.cognitoUserPoolClient] });
this.api = new sst.Api(this, "Api", {
customDomain: process.env.API_DOMAIN ? process.env.API_DOMAIN : undefined,
defaultThrottlingRateLimit: 500,
defaultThrottlingBurstLimit: 100,
defaultAuthorizationType: sst.ApiAuthorizationType.JWT,
defaultAuthorizer: authorizer,
defaultFunctionProps: {
environment: {
DB_CONNECTION_STRING: process.env.DB_CONNECTION_STRING,
},
}
});
this.api.addRoutes(this, {
// Authenticated routes
"POST /businesses": "src/businesses/create.main",
"DELETE /businesses/{id}": "src/businesses/delete.main",
"POST /businesses/{id}/reviews": "src/businesses/create_review.main",
"DELETE /businesses/{id}/reviews/{rid}": "src/businesses/delete_review.main",
// Public routes
"GET /categories/{categorySlug}/businesses": {
function: "src/businesses/list.main",
authorizationType: sst.ApiAuthorizationType.NONE,
},
}The configuration includes a custom domain for the API, set from an environment variable, JWT authorization for requests, some sensible throttling limits, and a database connection string which is passed to the handler functions. Above is an example of an authenticated route (requiring a user to be logged in) such as adding a new business, and a public route (open to anyone that visits the site) such as fetching businesses by category. The Vue client makes requests to API Gateway secured using JWT authentication. API Gateway checks with the Identity Pool to determine if the user has authenticated with the User Pool. API Gateway invokes the appropriate Lambda function and passes in the Identity Pool user. The handler functions are Node.js based Lambda functions which execute some backend logic, like saving or retrieving a record from the database, and returning a json response to the client.
Cron
I utilised cron jobs to generate counters, badges, scores and cleanup tasks. Counters are used to track things like number of interactions with a business. Badges are used to label businesses as “New” and “Trending”. Scores are normalised, numerical, and sortable values that are used for sorting and badge allocation. Cleanup tasks are used to keep the database light.
const cronScoresTrending = new sst.Cron(this, "cronScoresTrending", {
schedule: "cron(15 1 * * ? *)", // 01:15 AM (UTC) every day.
job: {
handler: "src/cron/scores_trending.main",
environment: {
DB_CONNECTION_STRING: process.env.DB_CONNECTION_STRING,
},
}
});
const cronCountsReviews = new sst.Cron(this, "cronCountsReviews", {
schedule: "cron(15 1 * * ? *)", // 01:15 AM (UTC) every day.
job: {
handler: "src/cron/counts_reviews.main",
environment: {
DB_CONNECTION_STRING: process.env.DB_CONNECTION_STRING,
},
}
});
const cronBadgesNew = new sst.Cron(this, "CronBadgesNew", {
schedule: "cron(15 1 * * ? *)", // 01:15 AM (UTC) every day.
job: {
handler: "src/cron/badges_new.main",
environment: {
DB_CONNECTION_STRING: process.env.DB_CONNECTION_STRING,
},
}
});The tasks are scheduled using a typical cron construct. Internally this uses AWS EventBridge. The handler lambda function is called and the database connection string is passed to it via an environment variable.
Database
DynamoDB, despite being pushed by AWS, has a very specific and limited use case. You’re going to have a tough time if your data is relational and transactional in nature and you need flexible, performant queries. I initially used RDS, however, after a months usage without a single hit, I discovered a charge in excess of $150USD. Part of that cost was from a managed NAT Gateway which is automatically provisioned when utilising RDS within a VPC. This is by far the most expensive service and way beyond what I am prepared to pay for a hobby site. Therefore, I moved to Heroku for dev, and DigitalOcean for prod. They both have very simple managed offerings. The connection strings are stored in environment variables.
That’s mostly it for the backend. With that, a scalable and worry-free infrastructure is in place, including a relational database, object storage, user management and authentication, API endpoints, and a way to run backend application logic. I could tie in additional services, and there are hundreds of them, but that’s all I needed for now.
The Frontend
The frontend is where the bulk of the work is. The serverless model lets you focus on what makes your app unique, the functionality and presentation of your offering. I built the frontend using Vue.js. Since the focus of this blog is how I utilised Serverless I won’t cover any of the internals of the Vue app itself.
const site = new sst.StaticSite(this, "TradesACTSite", {
path: "frontend",
customDomain: process.env.SITE_DOMAIN ? process.env.SITE_DOMAIN : undefined,
buildOutput: "dist",
buildCommand: "npm run build",
errorPage: sst.StaticSiteErrorOptions.REDIRECT_TO_INDEX_PAGE,
environment: {
VUE_APP_API_URL: api.customDomainUrl || api.url,
VUE_APP_REGION: scope.region,
VUE_APP_BUCKET: bucket.bucketName,
VUE_APP_USER_POOL_ID: auth.cognitoUserPool.userPoolId,
VUE_APP_IDENTITY_POOL_ID: auth.cognitoCfnIdentityPool.ref,
VUE_APP_USER_POOL_CLIENT_ID: auth.cognitoUserPoolClient.userPoolClientId,
VUE_APP_RECAPTCHA_SITEKEY: process.env.VUE_APP_RECAPTCHA_SITEKEY,
},
cfDistribution: {
additionalBehaviors: {
'public/*': {
origin: new origins.S3Origin(bucket.s3Bucket, {
originAccessIdentity: bucket.OriginAccessIdentity,
}),
allowedMethods: cloudfront.AllowedMethods.ALLOW_ALL,
compress: true,
viewerProtocolPolicy: cloudfront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
},
},
}
});The StaticSite construct deploys the Vue app to an S3 bucket, creates a CloudFormation distribution, and configures the custom domain for it. Environment variables are passed to the Vue app from the backend, including the API URL, uploads Bucket, and User Pool.
The custom Cloudfront distribution configuration allows Cloudfront to serve requests for the S3 bucket so that objects can only be accessed via the custom domain. This automatically creates the appropriate bucket policies.
Adding some protection
My biggest concern with being caught up in DDoS type attack is not the availability of the site, it’s the bill that I imagine would result from a spike in usage like that. I am unaware of an option to automatically pause/disable services if a predefined budget is reached.
To mitigate this I have set low but reasonable burst and rate limits on the API. If these limits are reached, the API will be throttled.
I have also proxied the website and API through Cloudflare. This means that all traffic to the web app passes through Cloudflare before it hits my services. AWS WAF is then used to restrict access to the site to Cloudflare’s IP addresses, ensuring that all traffic passes through the proxy. Cloudfare’s free tier provides basic DDoS protection, bot mitigation, CDN, and has an “under attack mode” which can be switched on in the event of an attack to enable an array of additional security measures.
Providers and pricing
The big name providers have very complex pricing models and are expensive when compared to the smaller players. Providers like Cloudflare, Wasabi, DigitalOcean, and Linode are significantly more affordable and predictable in pricing. Wasabi for example, advertises an 80% saving over S3. A stack that combines these cheaper providers, for example Cloudflare Workers for CDN, API and backend logic, Wasabi for storage, and DigitalOcean for database, would bring significant savings over a pure AWS setup. I plan to explore this further.
Tradesact.com.au features
A little about the features of tradesact.com.au.
- Homepage
- How it works, a static explainer page.
- Browse by category like Builders, Electricians.
- Filter by badges, like New and Top Rated.
- View contact info.
- Add your business or contribute one.
- Dashboard for business users.
- Review a business.
- Claim a business.
- User accounts